0. 视频介绍¶
1. 基础功能¶
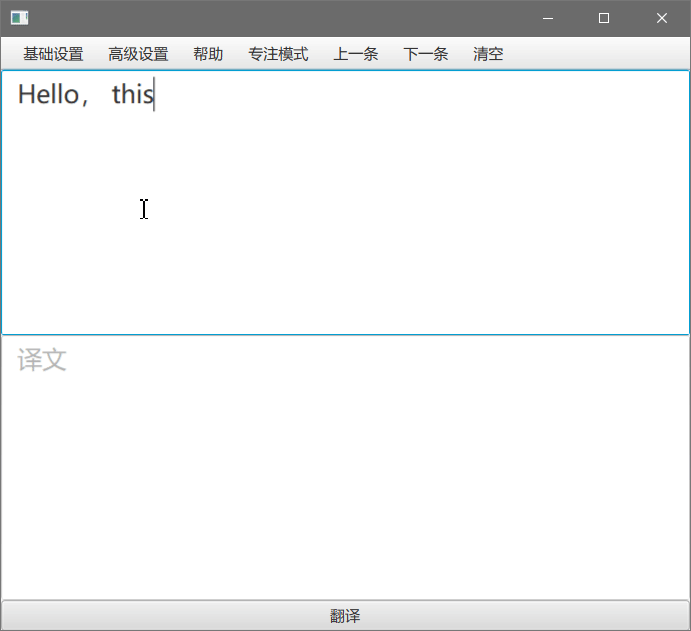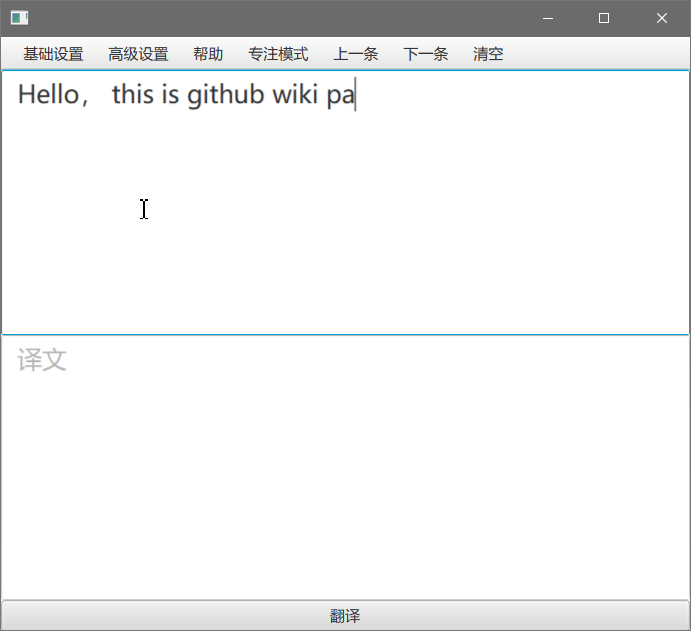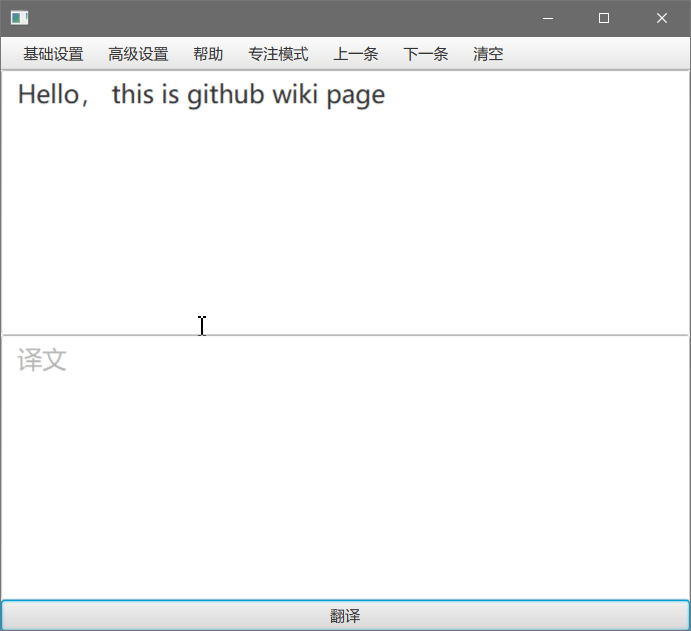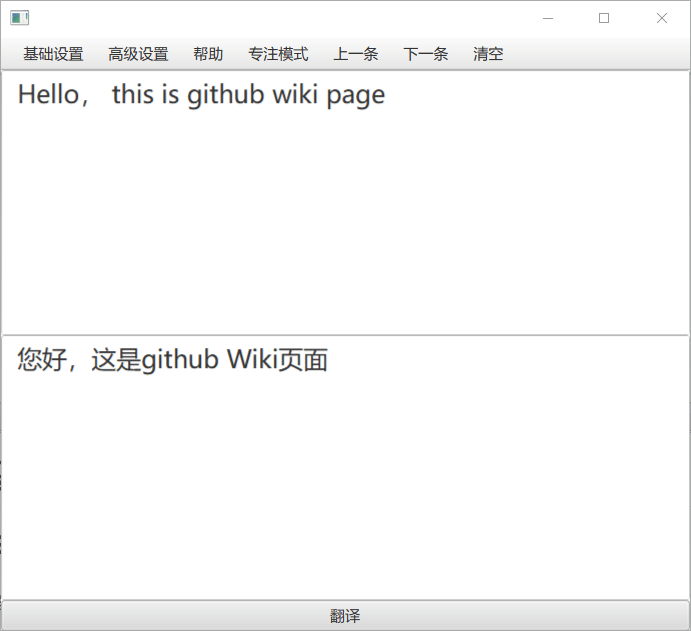
1.3 文本格式化¶
文本格式化是用来做什么的呢?我们平常在阅读 pdf 文档的时候,经常有这样的一个问题,从 pdf 中拷贝的文本粘贴到其它地方会多出很多换行,如:
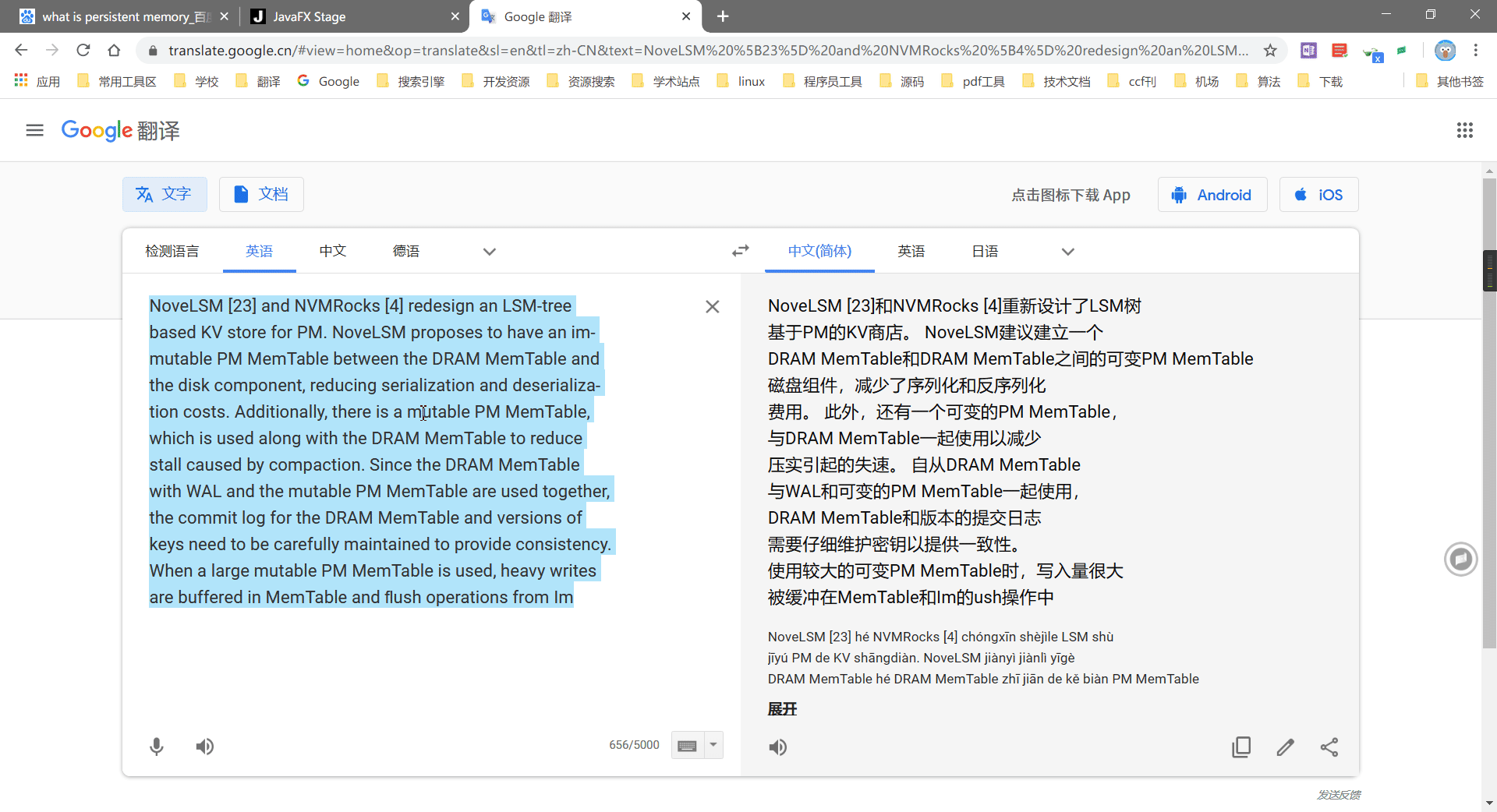
可以看到,因为多出很多空行,翻译会变得非常的不准确,一般来说,我们会手动替换掉所有的换行符,RubberTranslator 默认开启”文本格式化“功能,可以用来解决问题,在替换掉换行符的同时,尽量保持分段格式,功能展示:

1.4 监听剪切板¶
开启监听剪切板功能,只要 PC 剪贴板中有新文本或图片时,RubberTranslator 会自动翻译,也就是说只要有”复制“(Ctrl+C 或鼠标复制)动作,RubberTranslator 就会复制。如:

1.5 拖拽复制¶
每次都手动进行复制显得过于麻烦,所以拖拽复制可以实现自动复制,拖拽复制在以下两种情况下会触发:
鼠标双击;
鼠标点击->移动一定距离->释放。如果移动距离过近,则不会触发复制。
配置监听剪切板功能,即可实现自动翻译。演示:
双击:

拖拽:

1.6 自动复制¶
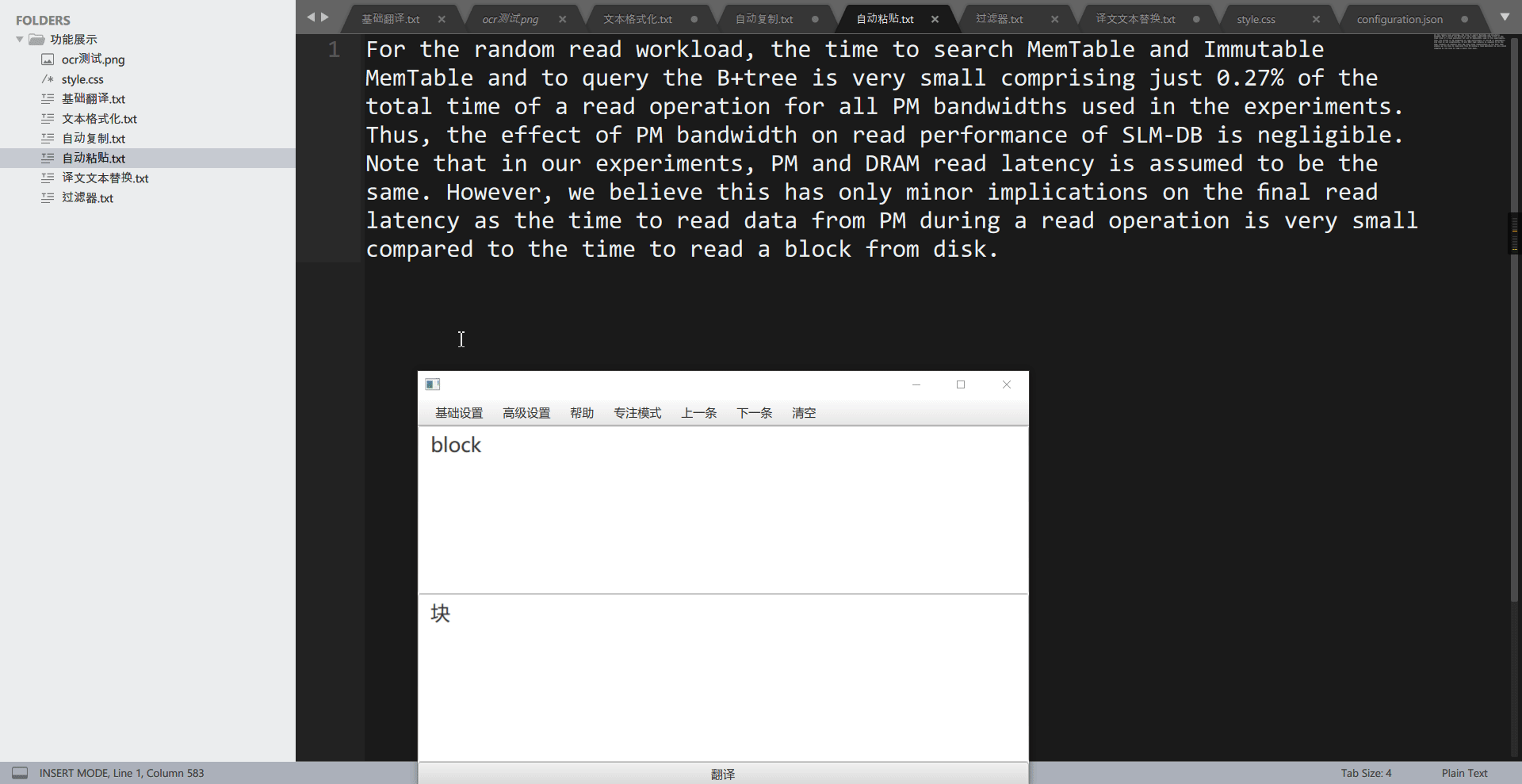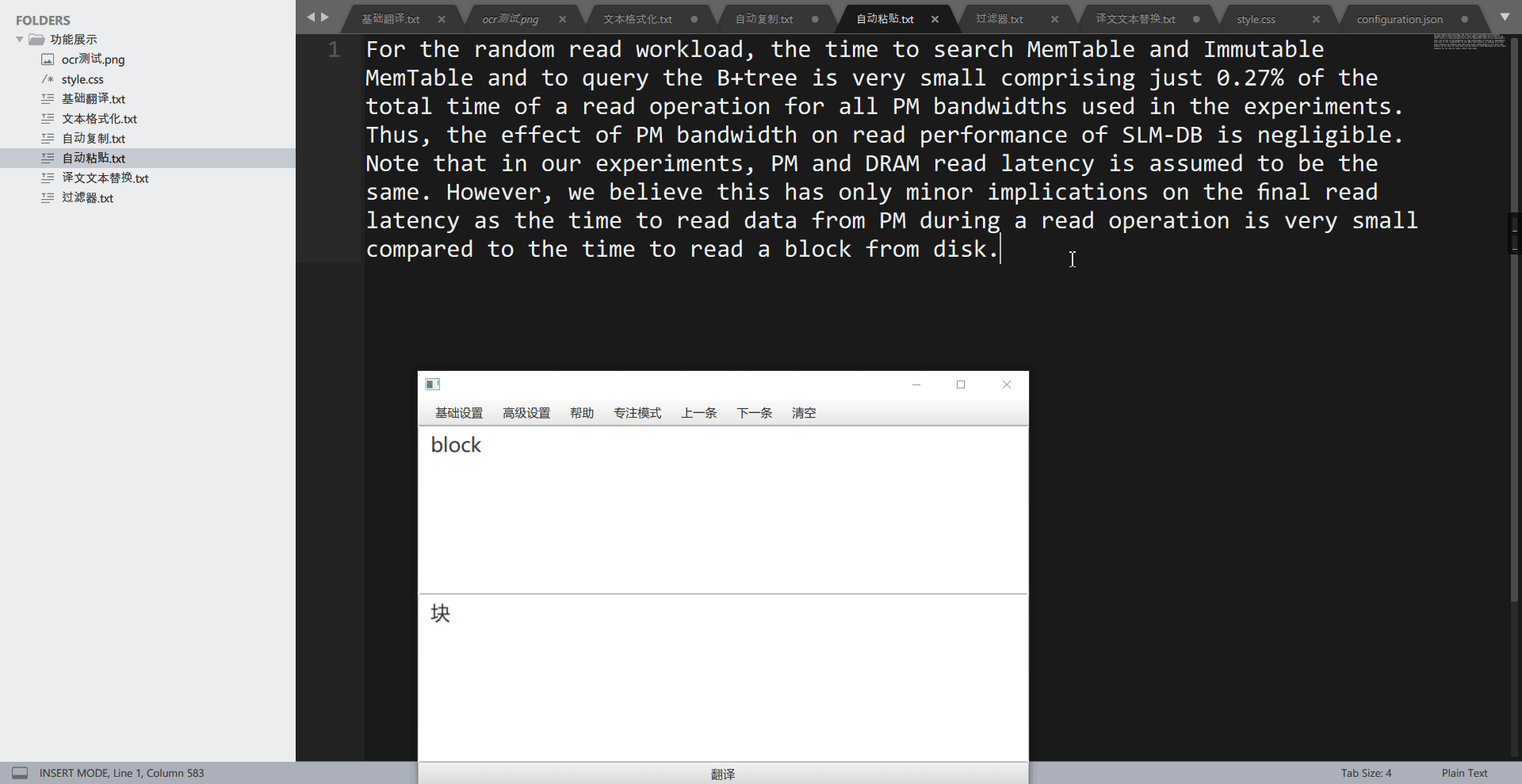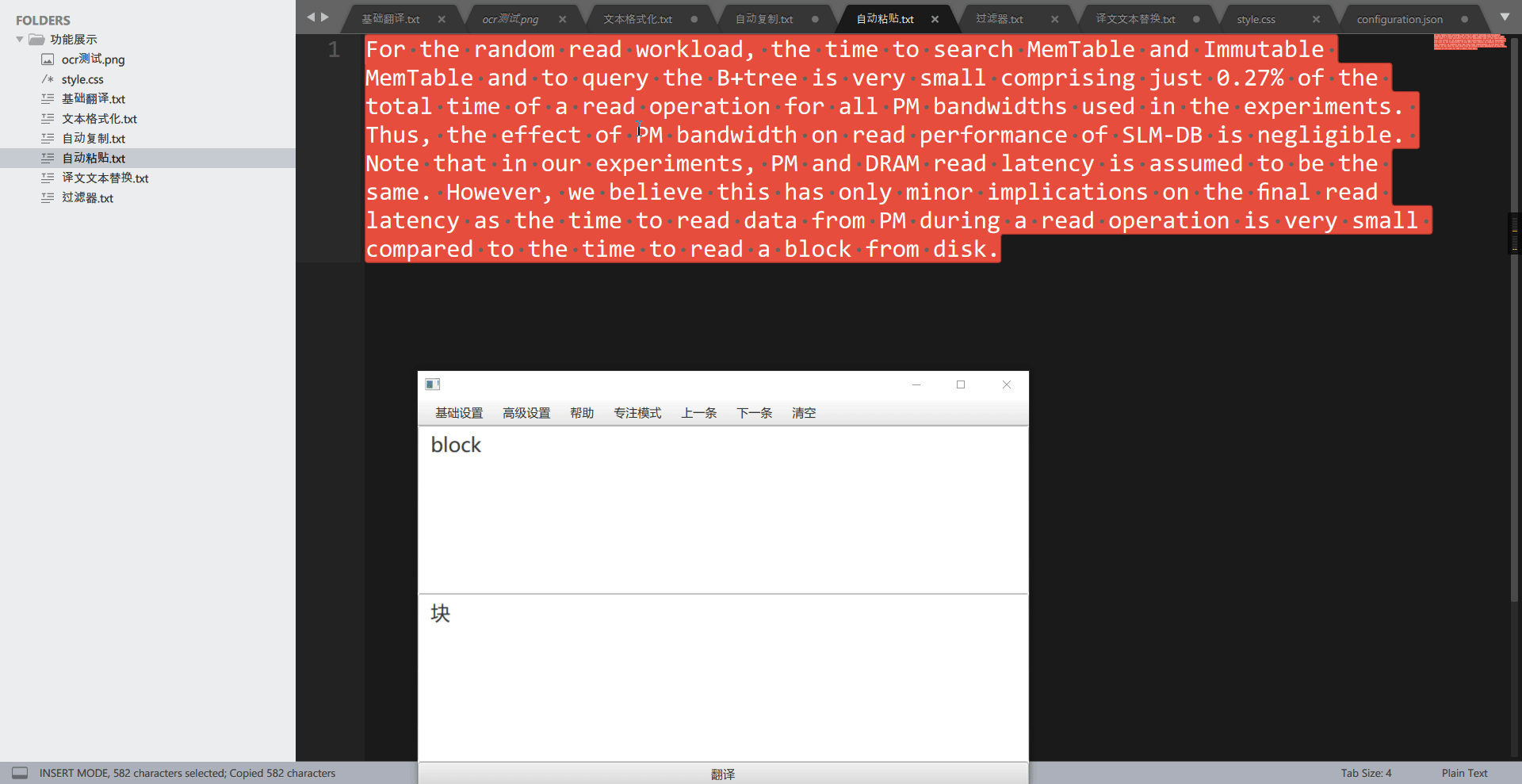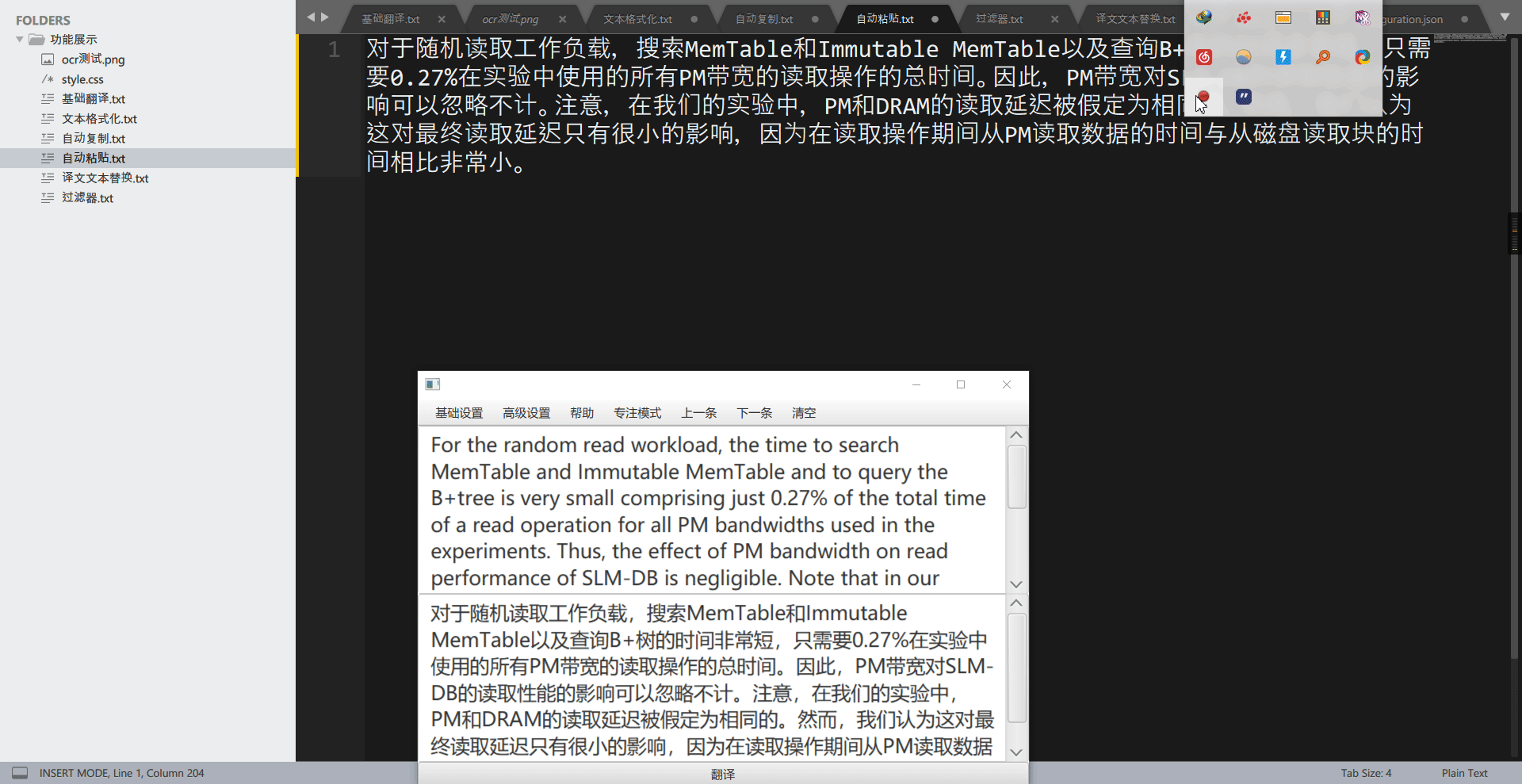
自动复制用于自动复制译文,RubberTranslator 在翻译完一段文本后,会自动将译文文本放入到系统剪切板中,此时用户通过”粘贴”功能即可在任何地方输入译文了。
tips: v3.6.3 后,可自动复制 OCR 原文,使用方法为,将”翻译引擎”改为”none”即可。

1.10 历史记录¶
RubberTranslation 也支持历史记录。

1.14 翻译接力¶
一直使用同一个翻译引擎时,可能会出现翻译失败的情况,在这种情况下,RubberTranslato 会自动选择下一个翻译引擎进行翻译。
2. 高级设置¶
1. 过滤器¶
此功能暂时仅限 Widnows 平台。
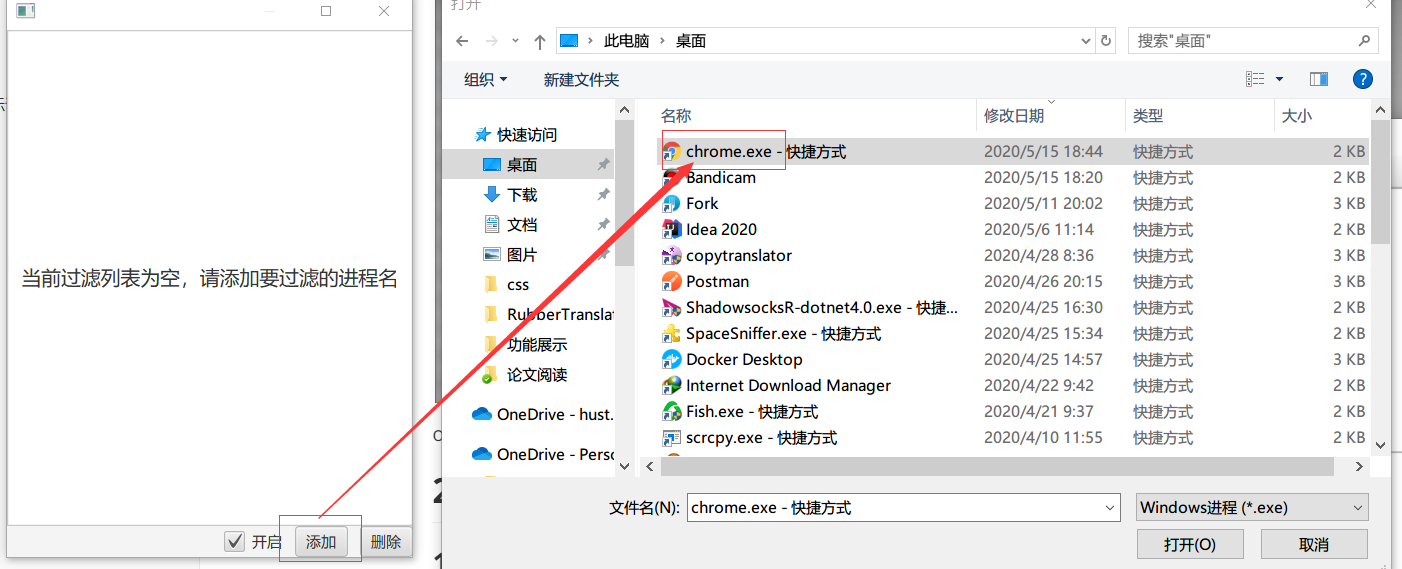
过滤器用于设置不需要进行复制翻译的程序,考虑一个场景,在看论文时,我们需要在浏览器中搜寻一些资料,但是我们并不需要自动翻译浏览器中的内容,这时就可以将浏览器加入我们的过滤名单中。
操作:高级设置->过滤器,点击添加,找到浏览器的 exe 文件(快捷方式也可以)即可:
2. 翻译文本替换¶
这个功能用于将译文中的特定词组替换为自己想要的词组,可以用于替换为专有名词。举个例子,在计算机数据结构或算法上,有一个术语叫做 binary search,一般中文称为二分查找,而使用翻译引擎翻译,则会被翻译为二进制搜索,这让人非常的别扭。通过”翻译文本替换“功能,我们可以还原为二分查找。
先看,没有添加词组前:
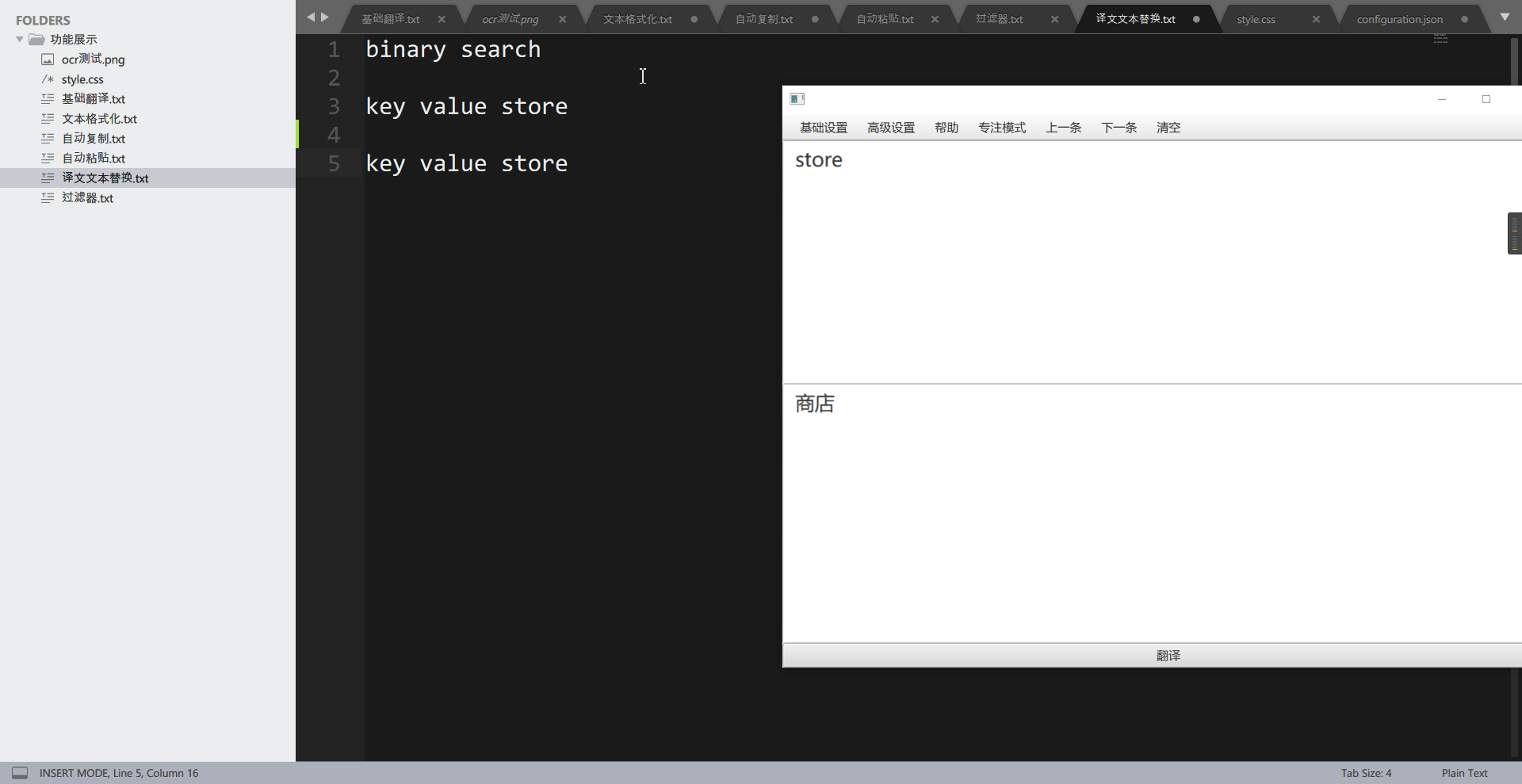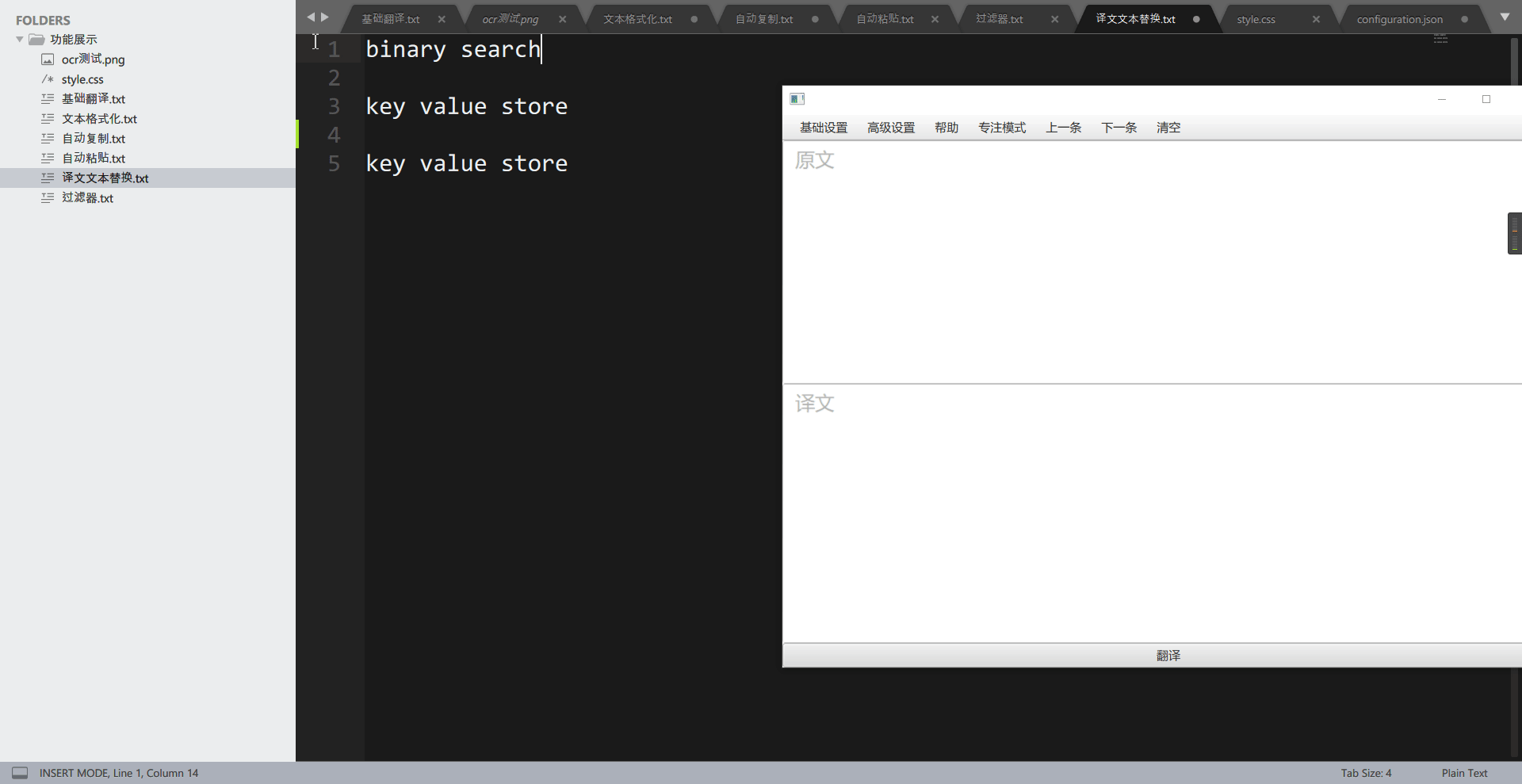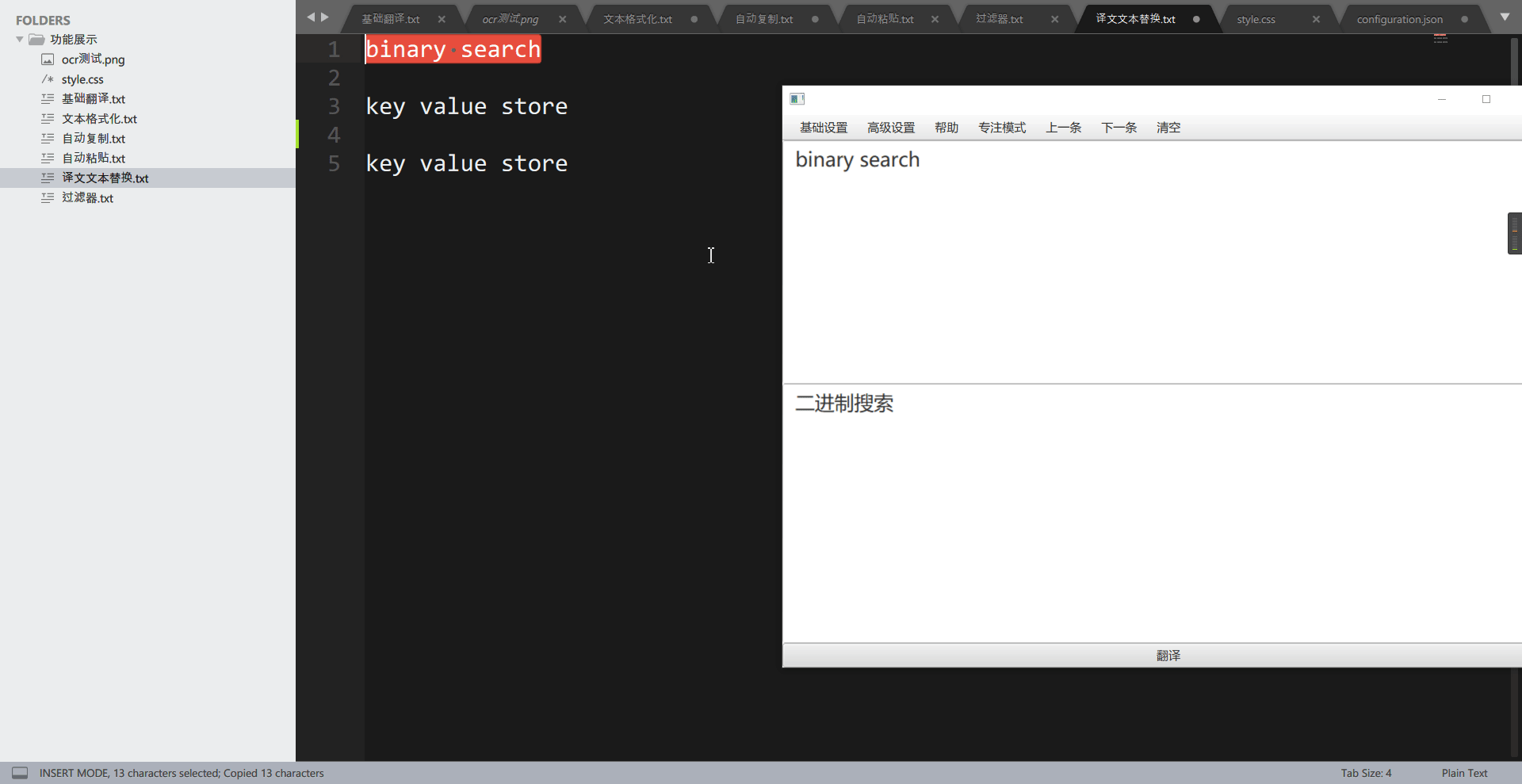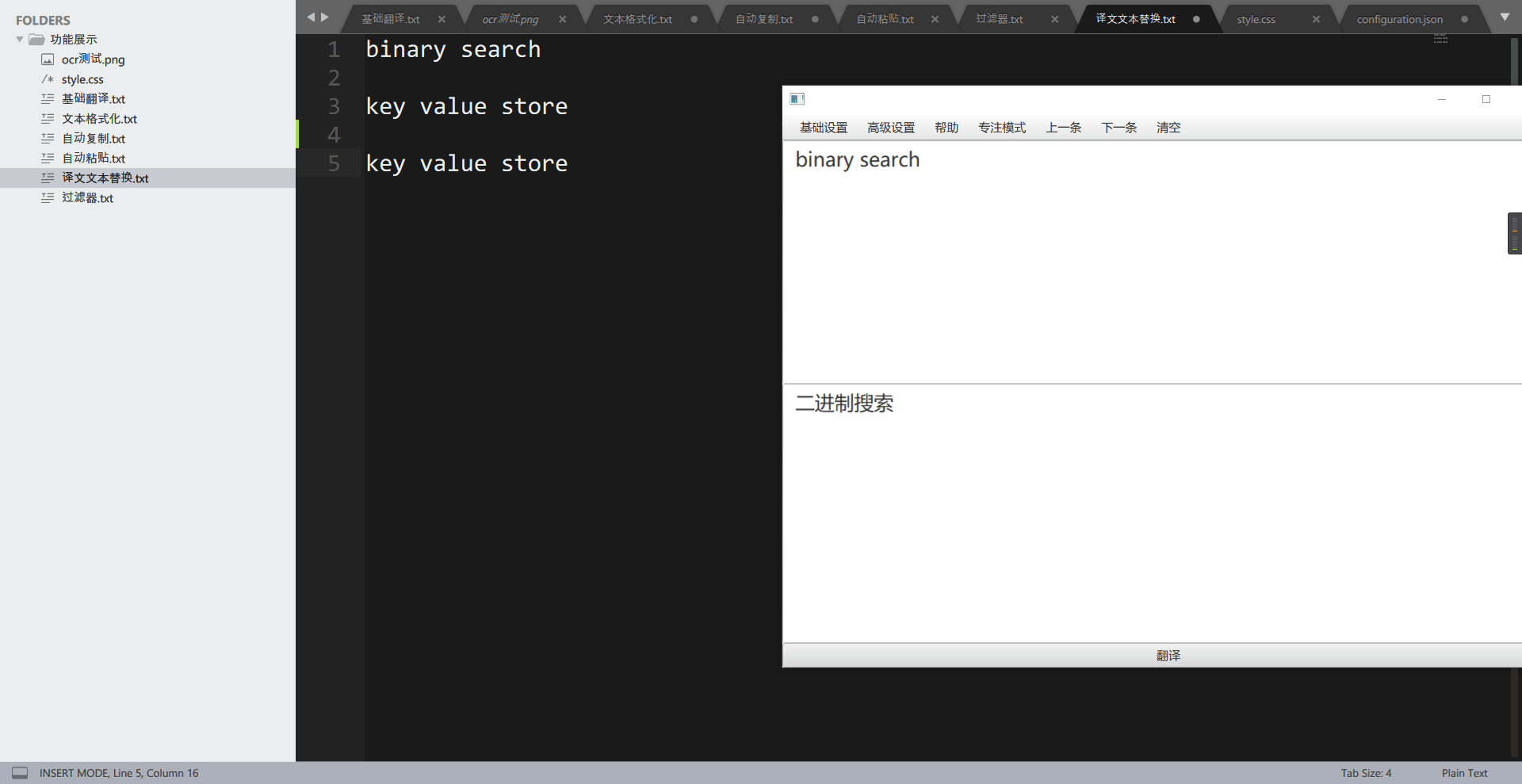
再看添加词组后:
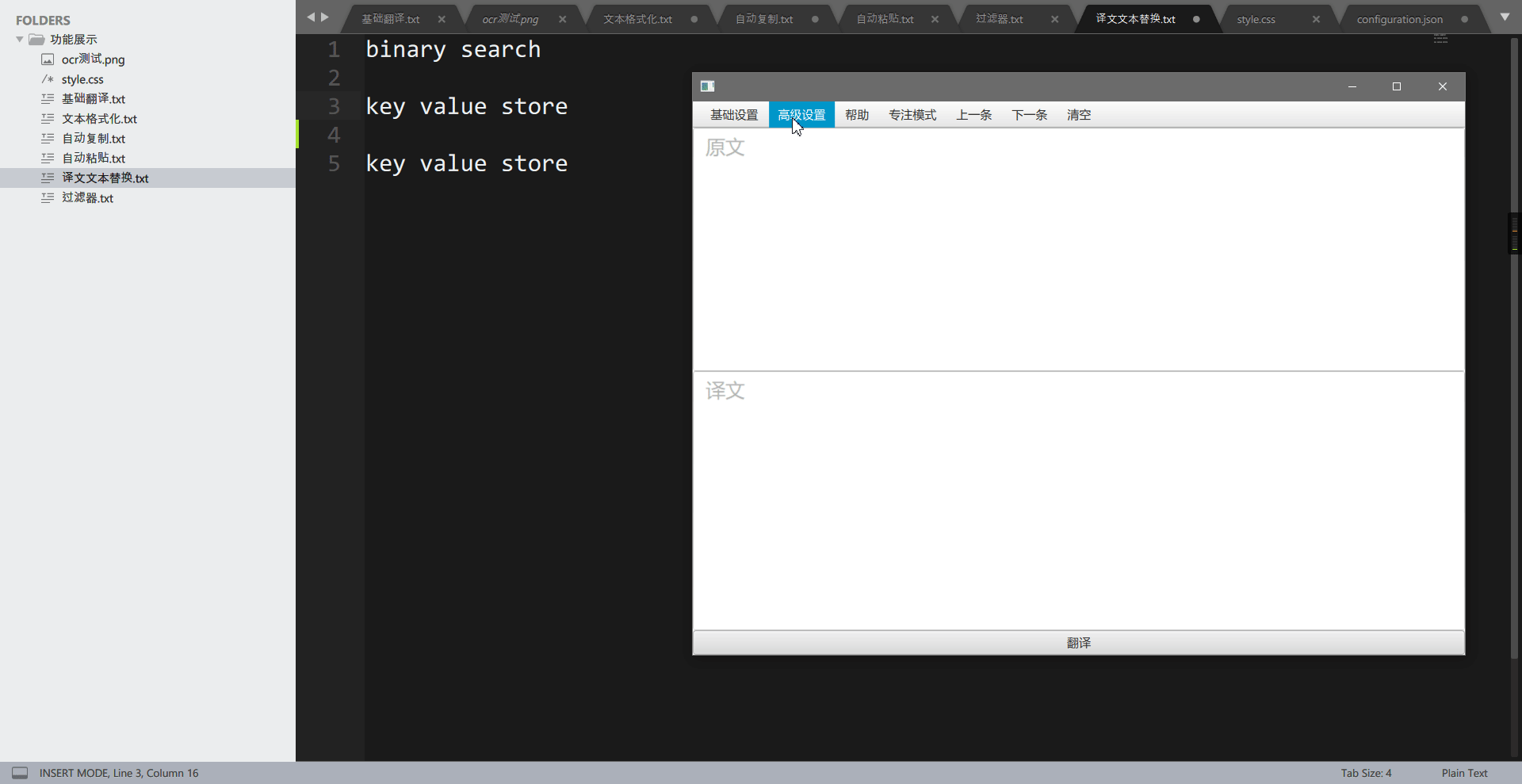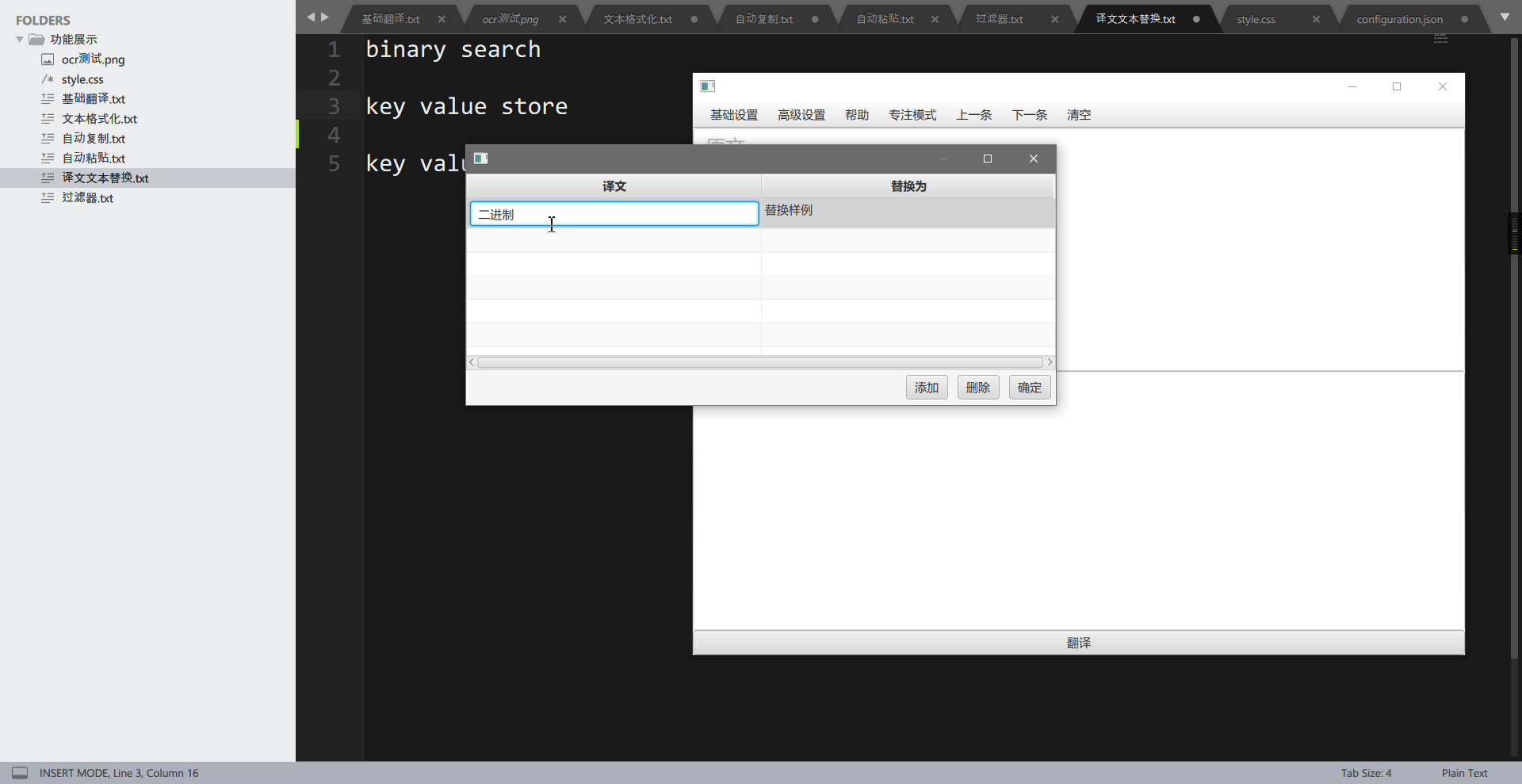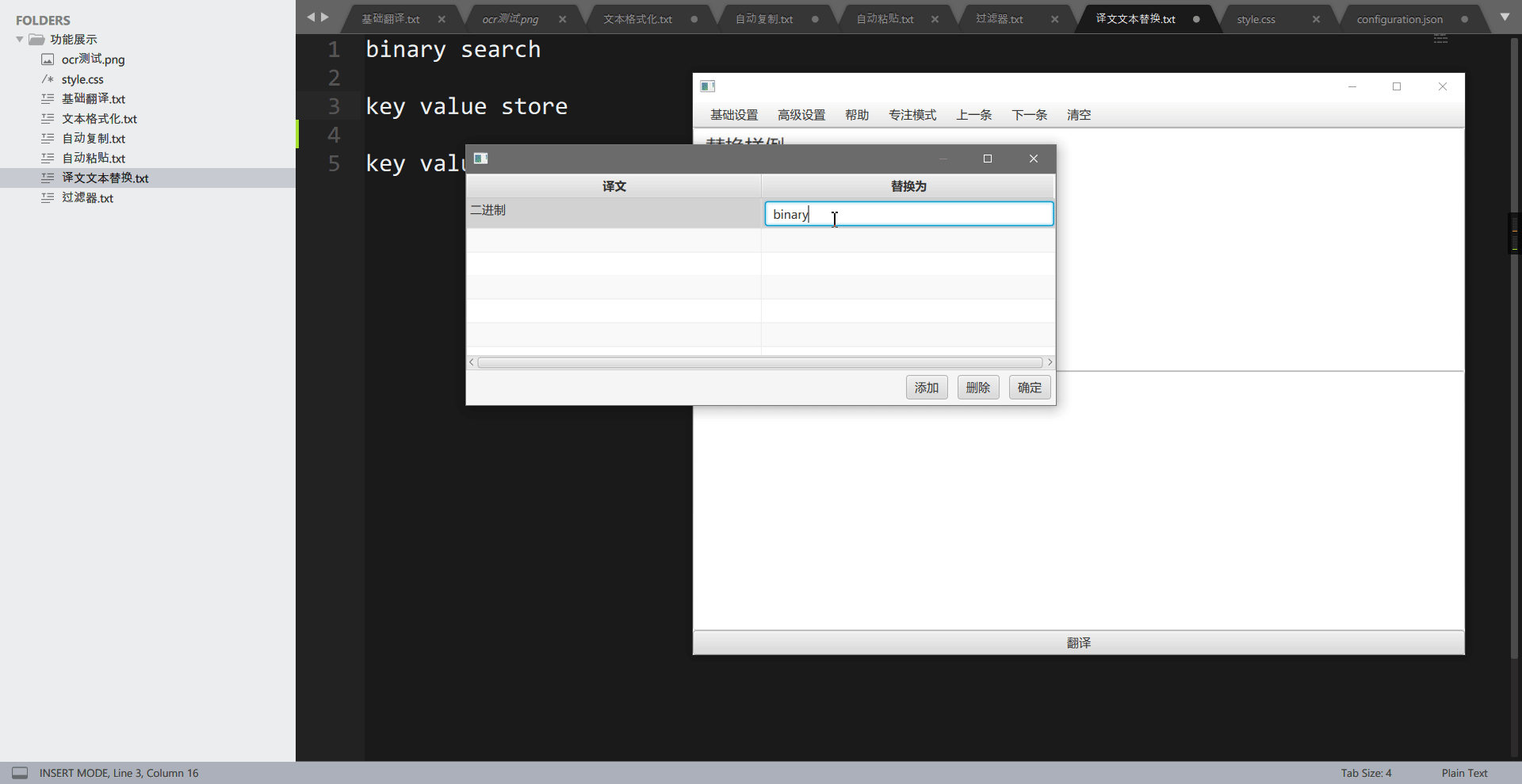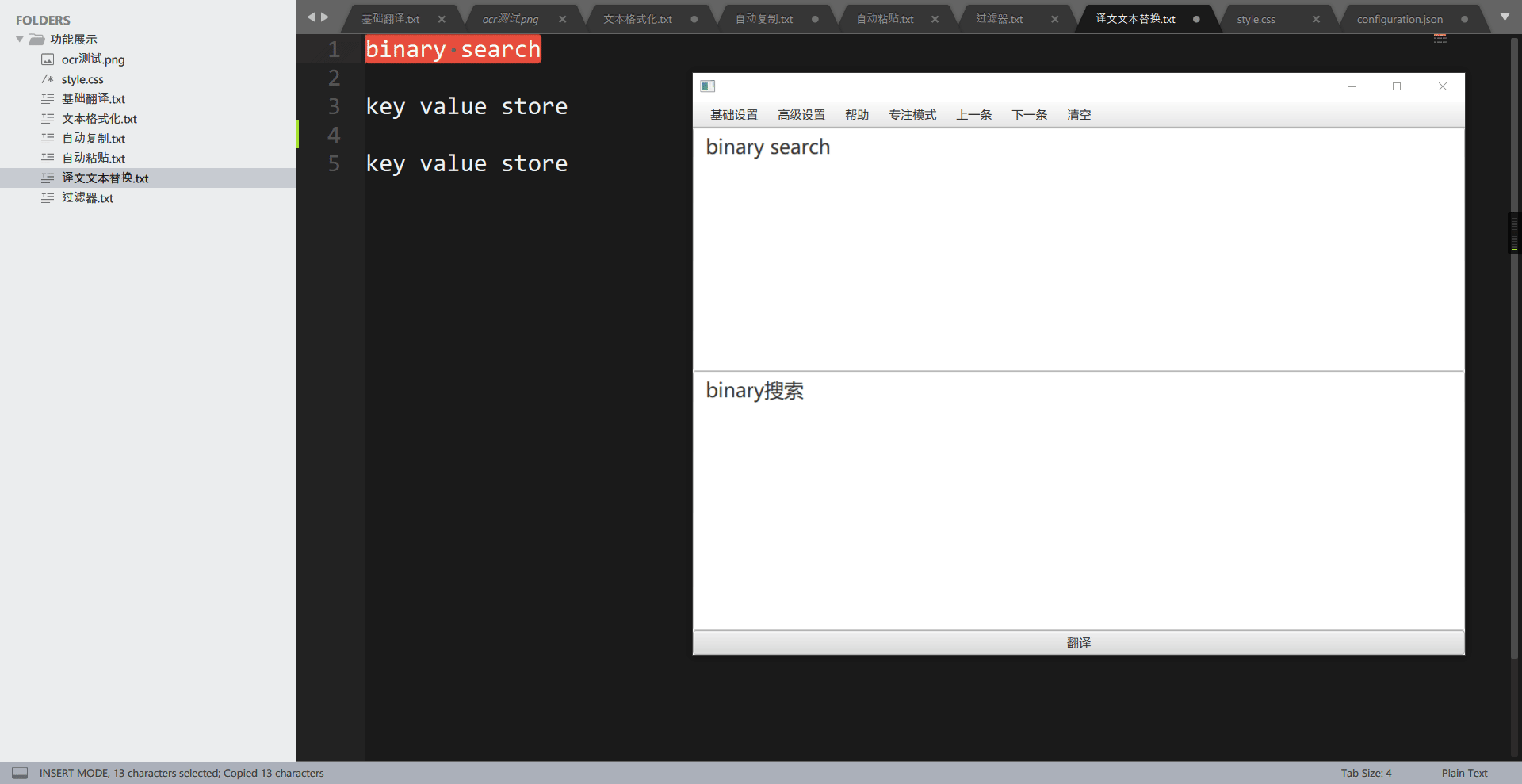
支持 java 正则表达式。
3. 翻译文本批量导入¶
如果你有大量词组需要导入,一条条输入是非常慢的,此时可以使用“批量导入”功能,如下:
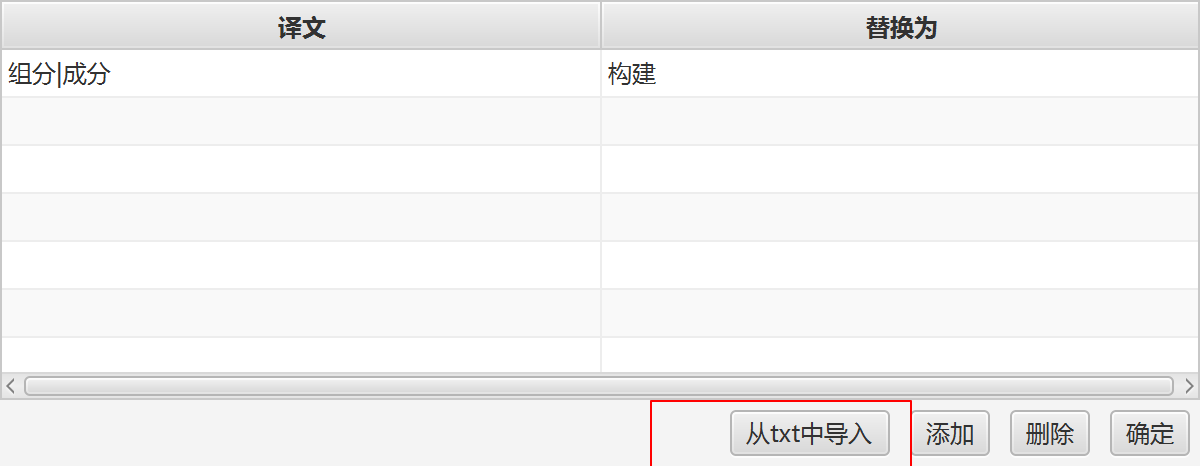
选中一个 txt 文件,这个 txt 文件存放的就是你的词组文件,具体格式为:
译文:替换为
每行一个词组。
如:
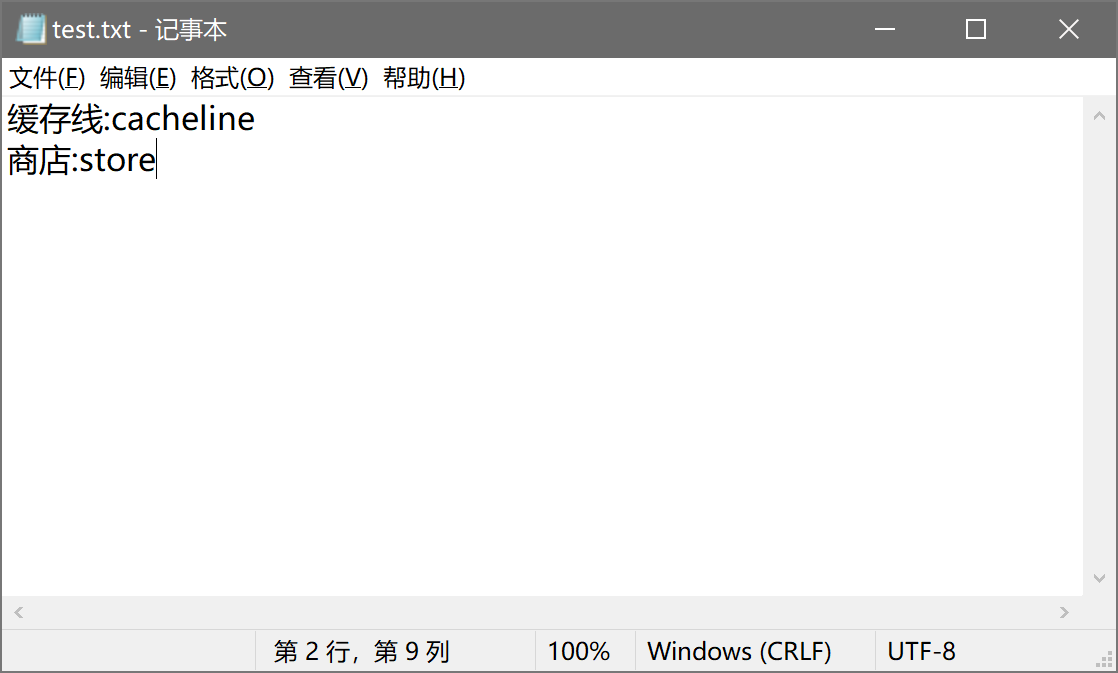
代表两个词组,将缓存线替换为 cacheline, 将商店替换为 store。
另外,如果重复选择一个 txt 文件,添加可能会看到重复行,如:

RubberTranslator 只会选择其中一组保存。
4. 历史记录数量设置¶
可以设置历史记录的数量,但注意历史记录在程序关闭后就会消失,每次重启应用都会重新记录历史。
~~5. 自定义样式~~¶
自 v3.6.0 开始,取消本功能。 改用 GUI 设置。
~~RubberTranslator 支持自定义 css 样式。 如,设置护眼模式,更改字体大小的 css:~~
#main {
/* 主模式 */
-fx-font-size: 10pt;
}
#focus {
/* 专注模式 */
}
#compare {
/* 对比模式 */
}
.text-area {
-fx-font-size: 10pt;
}
.text-area .content {
-fx-background-color: rgb(199, 237, 204);
}
效果:
更多可设置效果,请参考
6. OCR 百度和有道 APi 设置¶
3. 开源许可¶
GPL v3.0